
S3内のCSVファイルに対してAmazon Athenaでクエリ実行してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
かつまたです。
Amazon Athenaは標準的なSQLを使用して、S3内のデータを直接分析することを容易にするインタラクティブなクエリサービスです。今回はS3にアップロードしたCSVファイルに対しAmazon Athenaを利用してクエリを実行してみたため手順をご紹介していきたいと思います。
S3作成とCSVアップロード
クエリ対象である適当なCSVファイルの作成とアップロード先のS3の作成を行います。
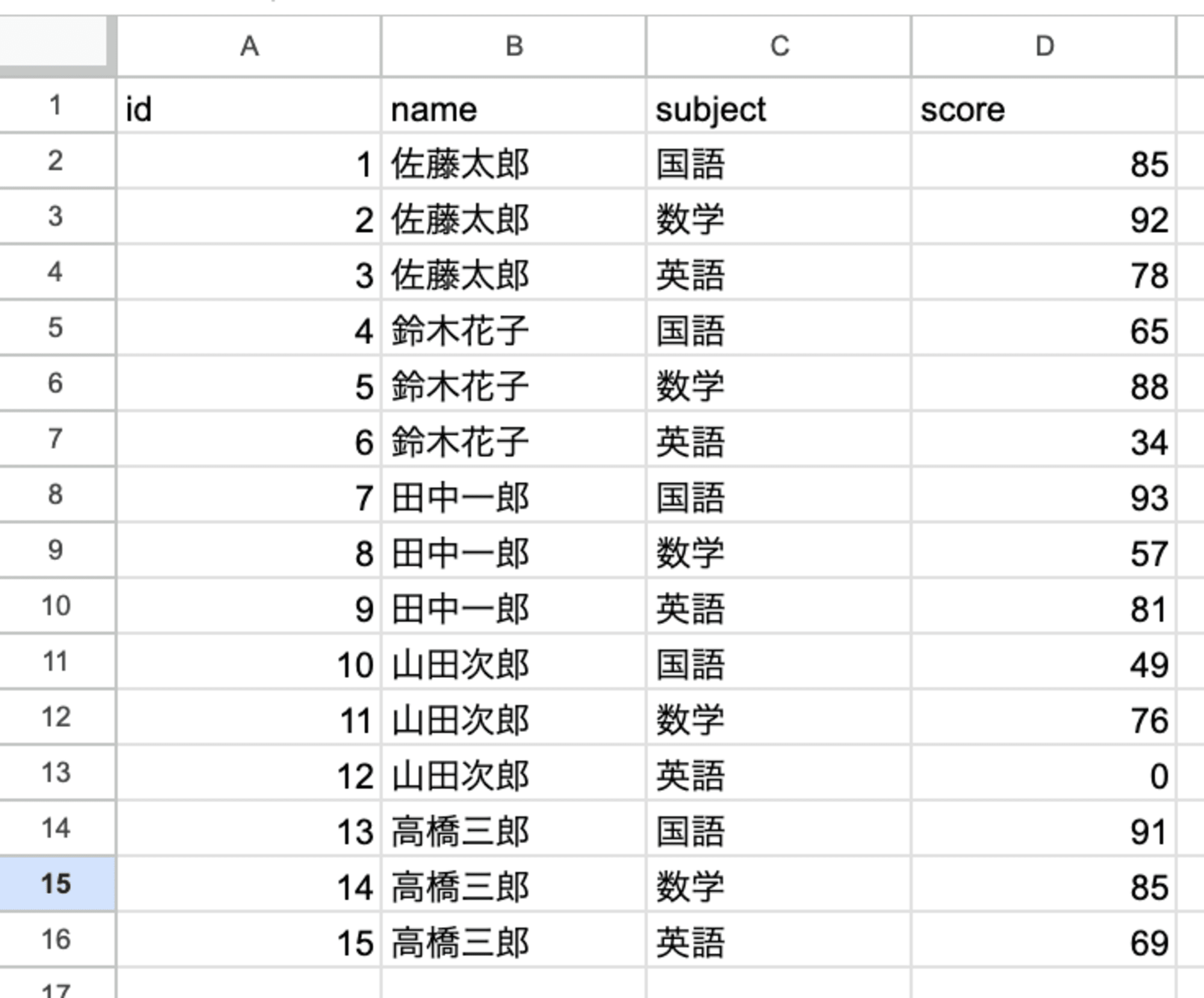
1.ローカルで適当なCSVファイルを作成、保存します。私はid,name,subject,scoreを項目とする15行のCSVファイルを作成しました。
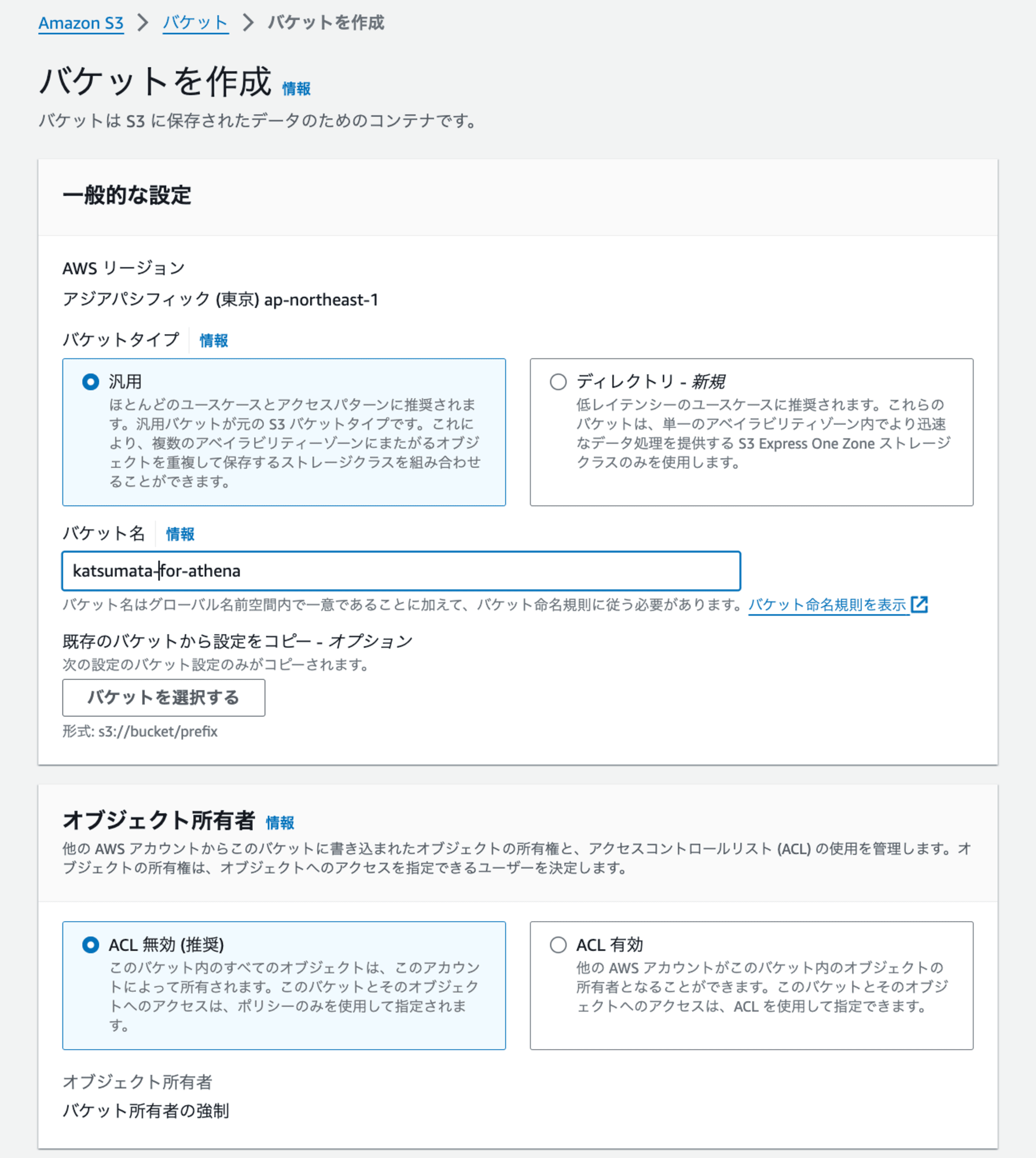
2.マネジメントコンソールの「S3」→「バケット」→「バケットを作成」からバケットを作成します。
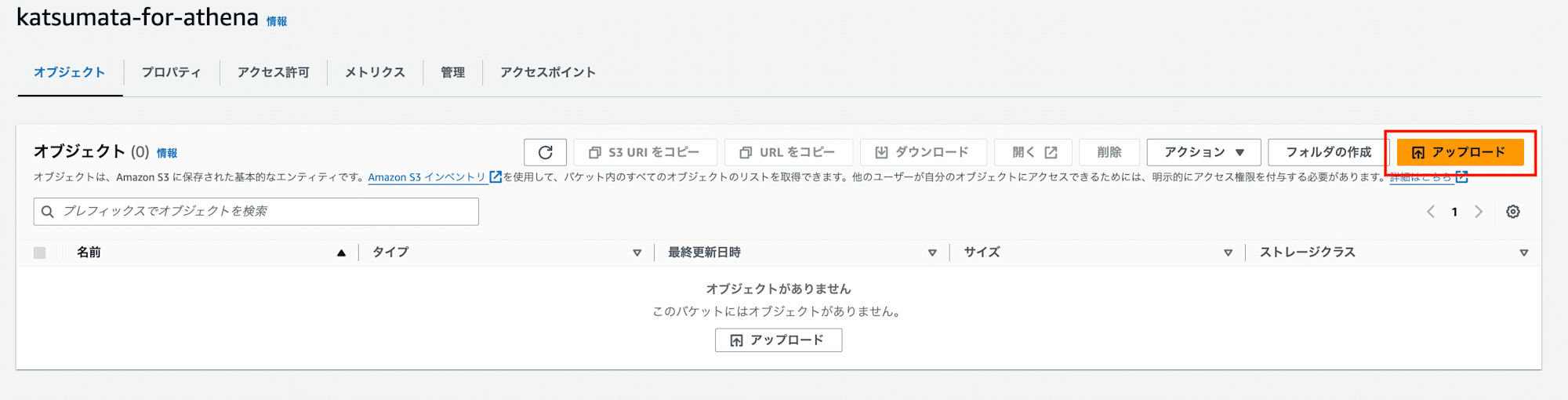
3.作成したバケットの「オブジェクト」→「アップロード」を押下し、「ファイルを追加」からローカルのCSVファイルをS3にアップロードします。
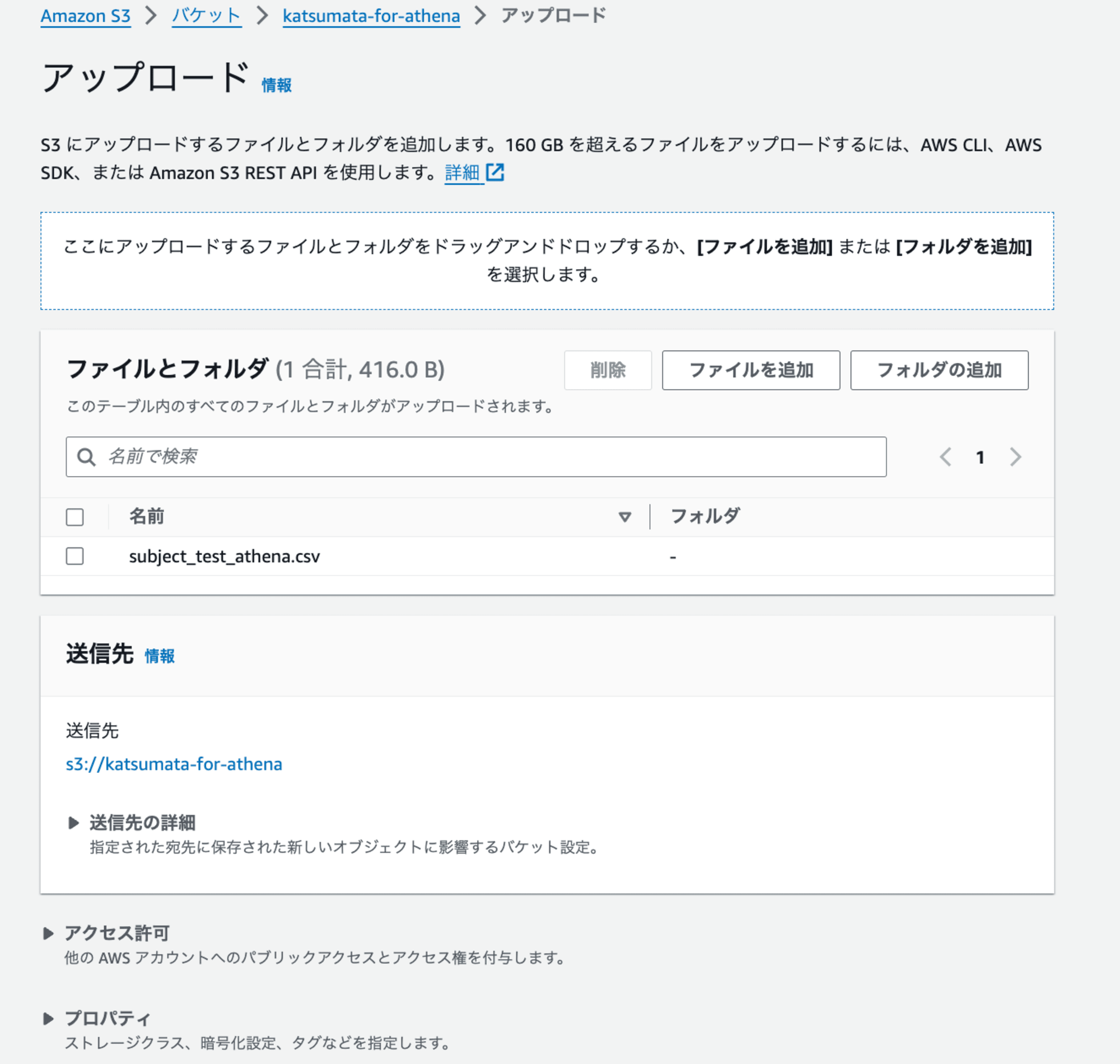
以上でS3側の設定は完了です。
Amazon Athena設定
Amazon Athena側で、S3内のCSVファイルをクエリ実行できる環境を設定していきます。
1.マネジメントコンソールの「Amazon Athena」→「クエリエディタを起動」(Trino SQL を使用してデータをクエリする選択)からクエリエディタに移動します。
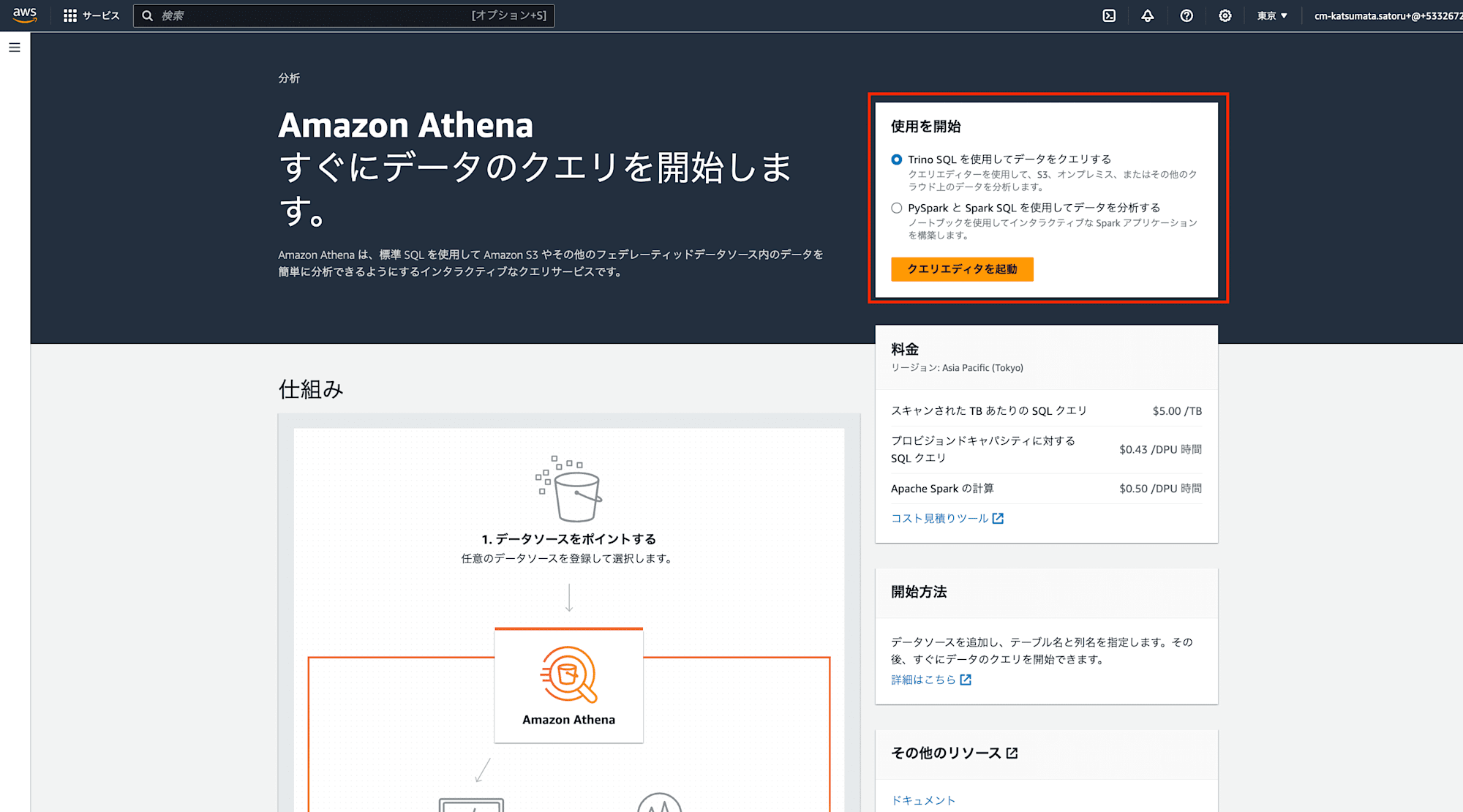
2.クエリ実行結果を保存するS3ファイル先を設定します。「設定」→「管理」から「S3を参照」を押下し、先ほど作成したS3バケットを選択します。

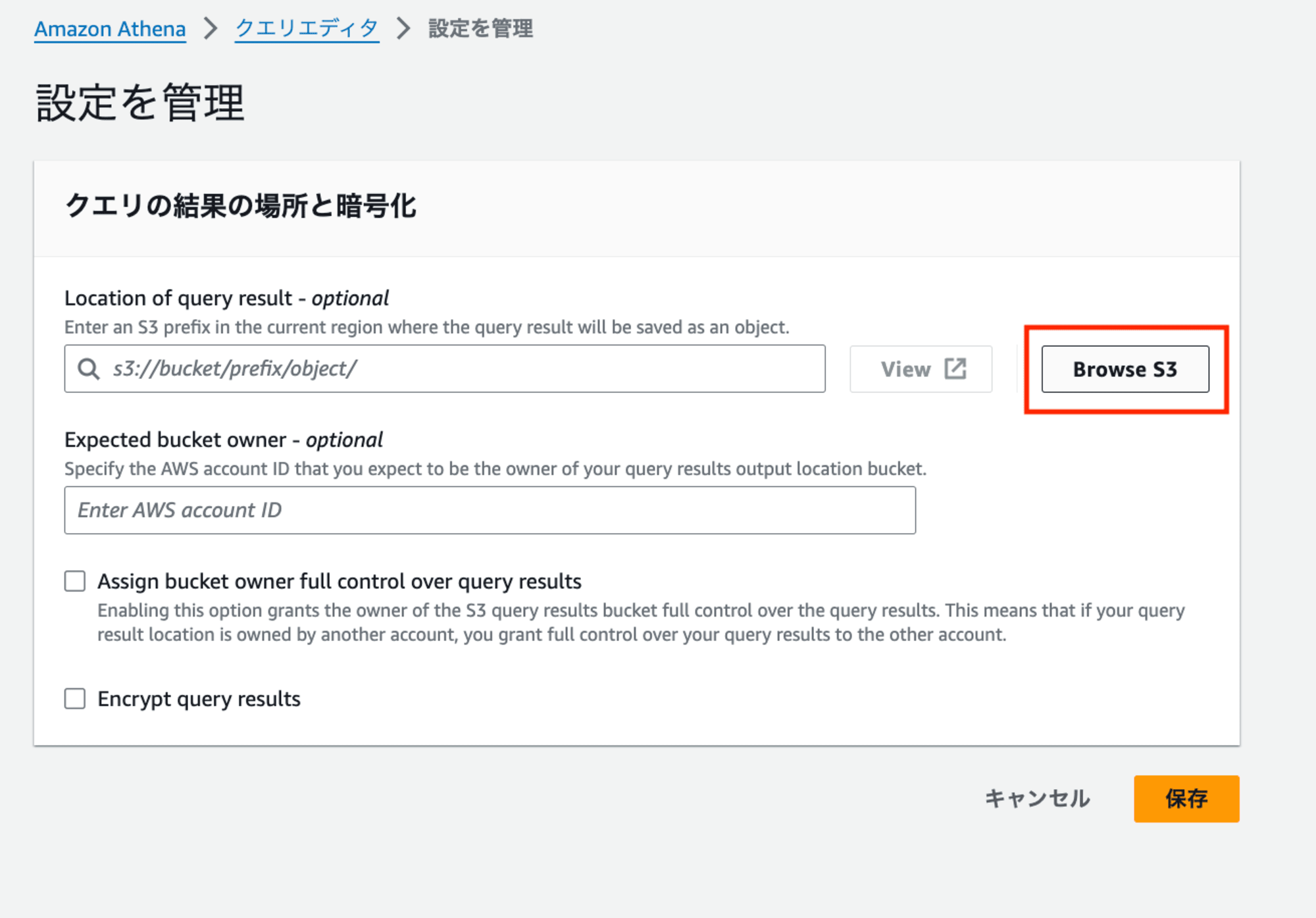
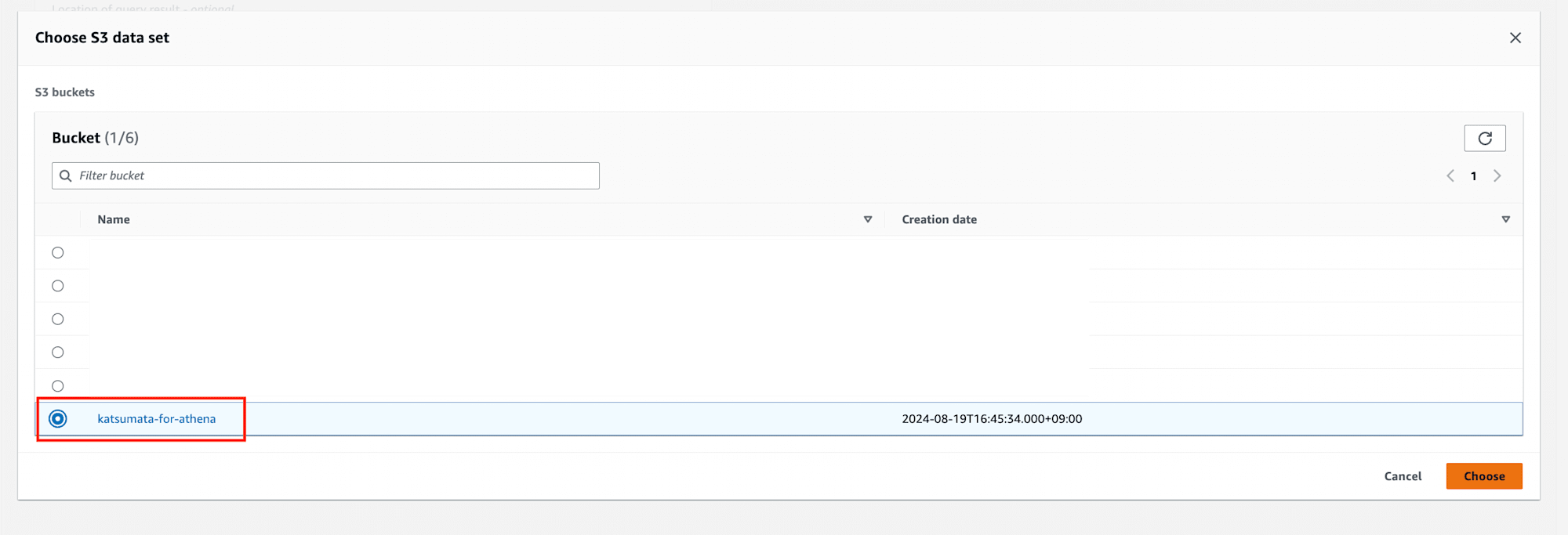
これによりクエリ結果の保存先を設定できました。
テーブル作成と確認
クエリのためにAmazon Athena上でテーブル作成を行う必要があります。
1.エディタ画面の「テーブルとビュー」項目の「作成」→「S3バケットデータ」を押下します。
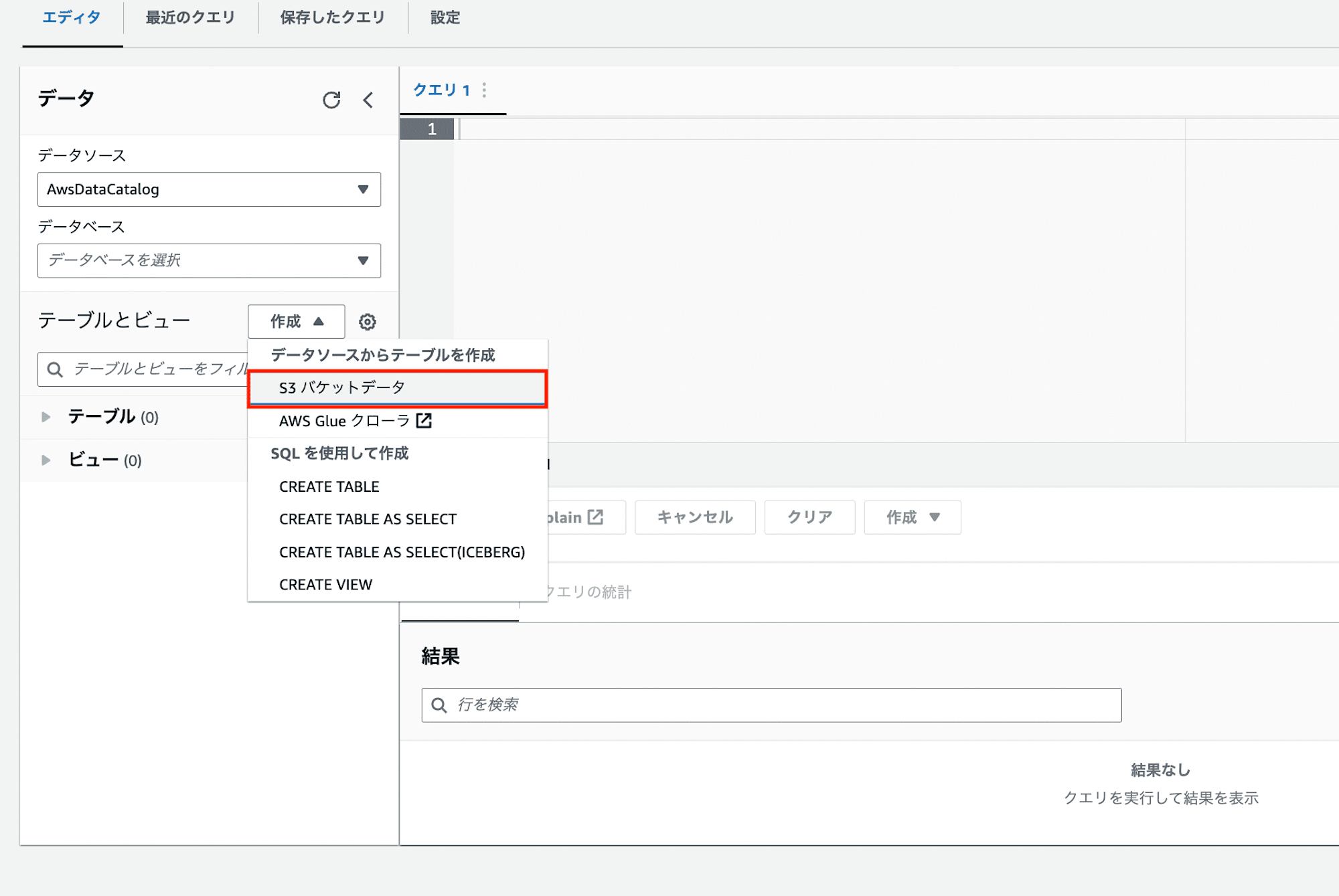
2.テーブル名と「データベースを作成」オプションのデータベース名を記入し、「入力データセットの場所」で作成したS3バケットを指定します。
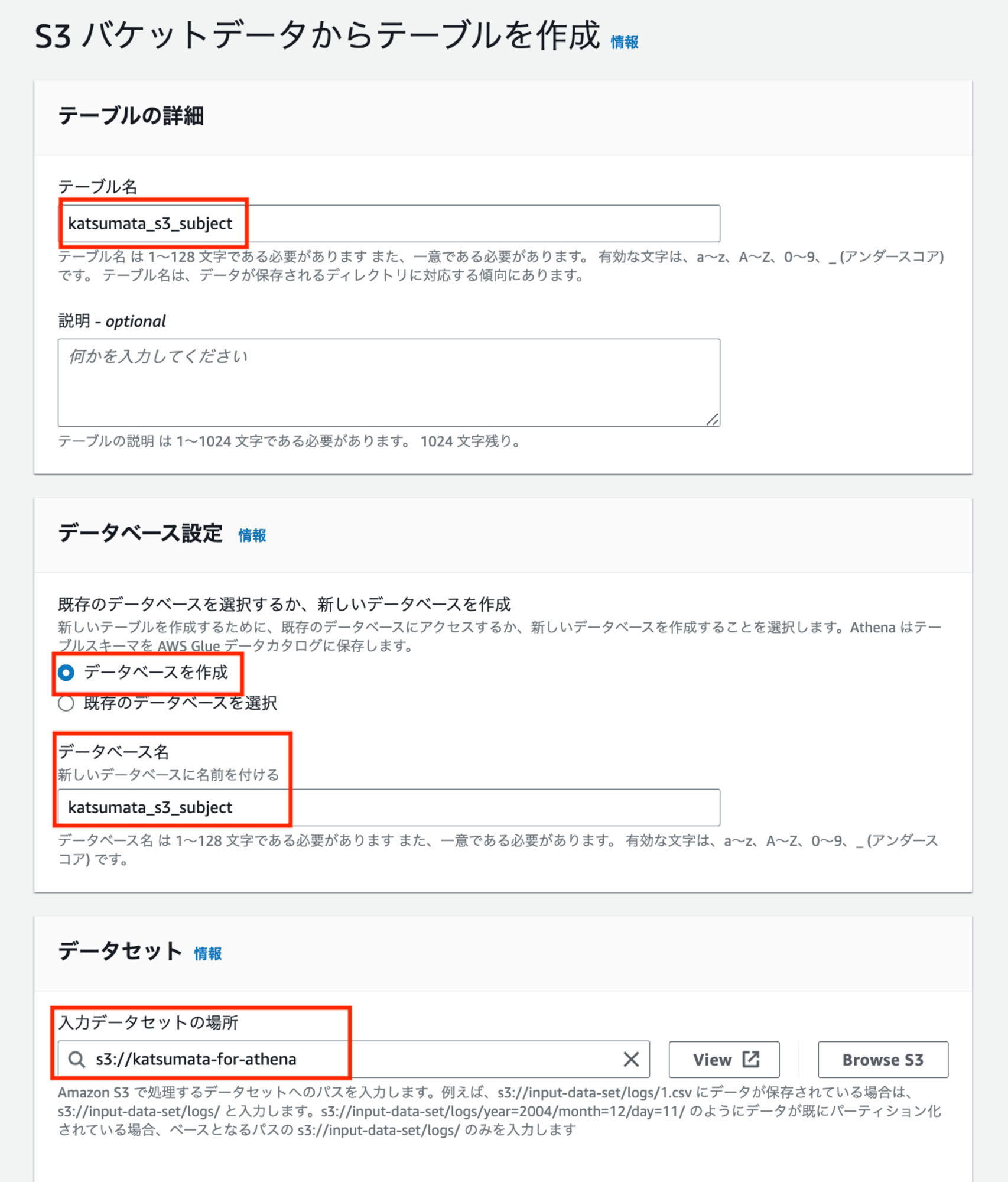
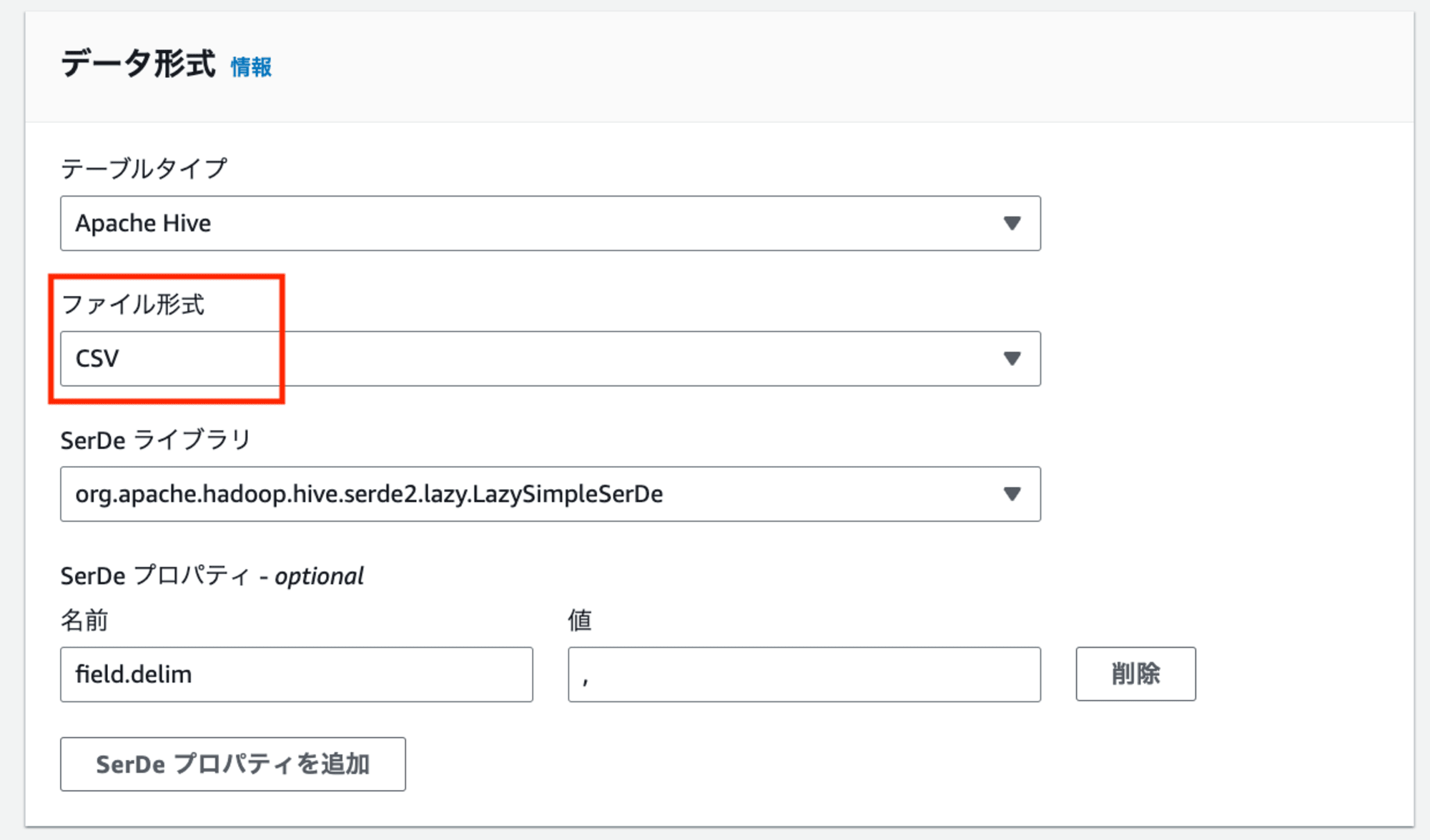
3.「データ形式」の「ファイル形式」をCSVに変更します。
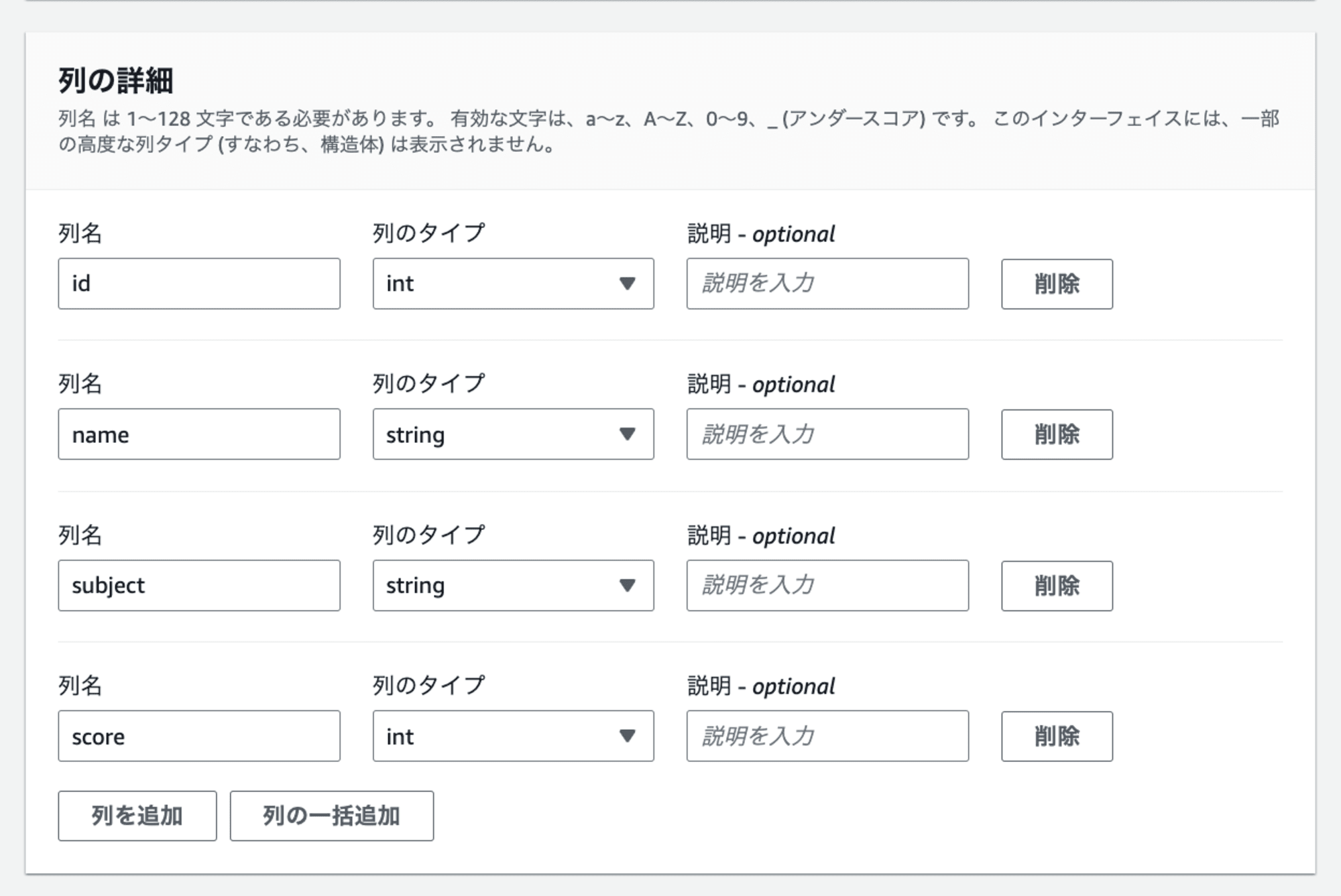
4.「列の詳細」でデータの列名と型を指定します。
5.「テーブルを作成」を押下します。
クエリ実行
作成したテーブルに対し、任意のSQLクエリを実行し、確認します。
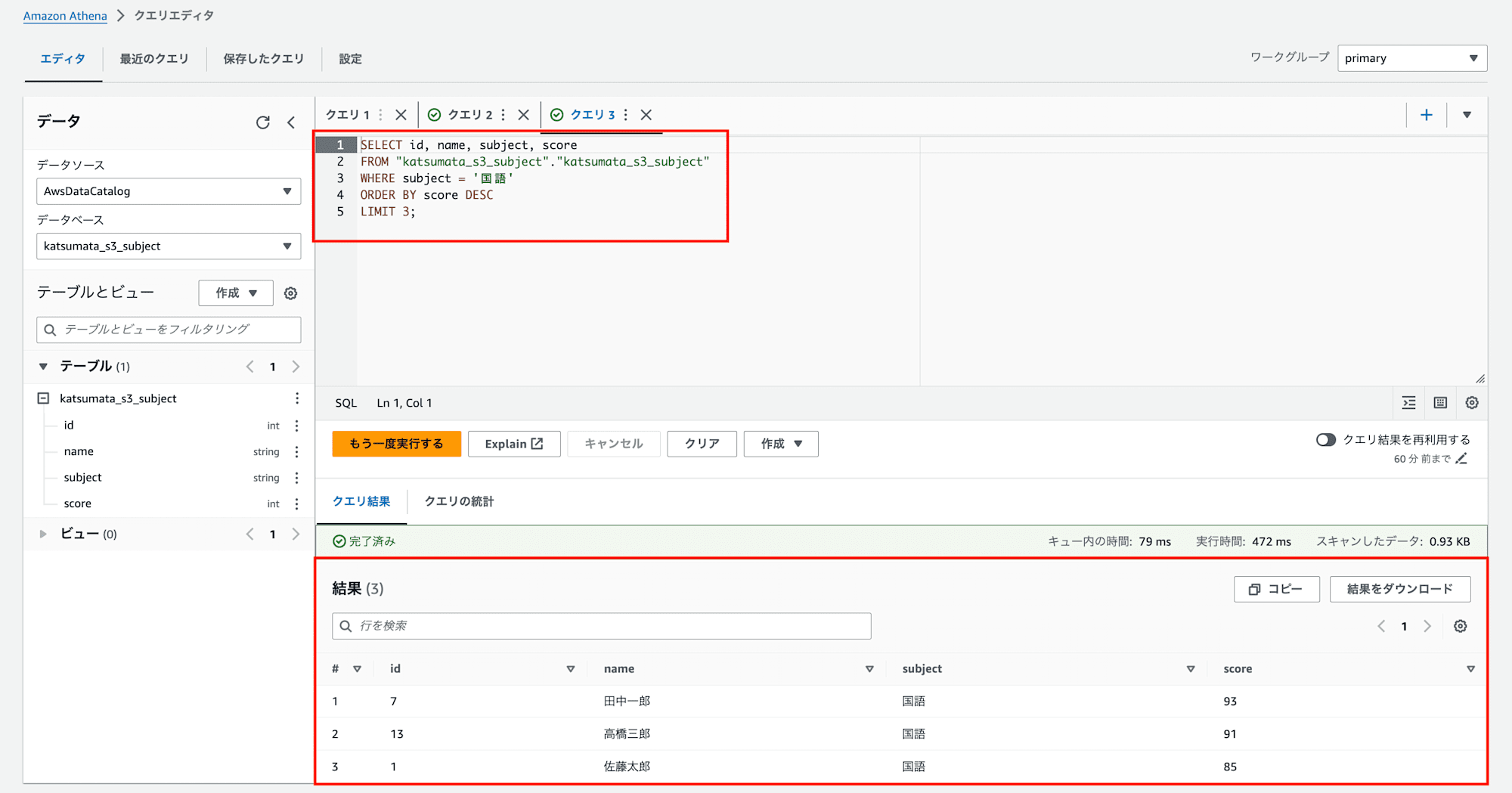
1.新しいクエリタブを開き、任意のSQL文を入力します。私はsubjectが国語である、scoreが上位3人のid,name,subject,scoreを取得するSQL文を入力しました。
SELECT id, name, subject, score
FROM "katsumata_s3_subject"."katsumata_s3_subject"
WHERE subject = '国語'
ORDER BY score DESC
LIMIT 3;
2.「実行」ボタンを押下すると「結果」に入力したSQL文に対するクエリ結果が出力されました。
終わりに
今回、Amazon Athenaを用いてCSVファイルに対し、クエリを実行してみました。視覚的にわかりやすく簡易的にクエリを実行することができると感じました。
今後、より複雑なクエリや大規模なデータセットに対するクエリについても試していきたいと思います。
ご覧いただきありがとうございました。
参考
アノテーション株式会社について
アノテーション株式会社はクラスメソッドグループのオペレーション専門特化企業です。サポート・運用・開発保守・情シス・バックオフィスの専門チームが、最新 IT テクノロジー、高い技術力、蓄積されたノウハウをフル活用し、お客様の課題解決を行っています。当社は様々な職種でメンバーを募集しています。「オペレーション・エクセレンス」と「らしく働く、らしく生きる」を共に実現するカルチャー・しくみ・働き方にご興味がある方は、アノテーション株式会社 採用サイトをぜひご覧ください。









